PlotPoints (Model Leaderboard)
Deep dives into every tool on stage
PlotPoints
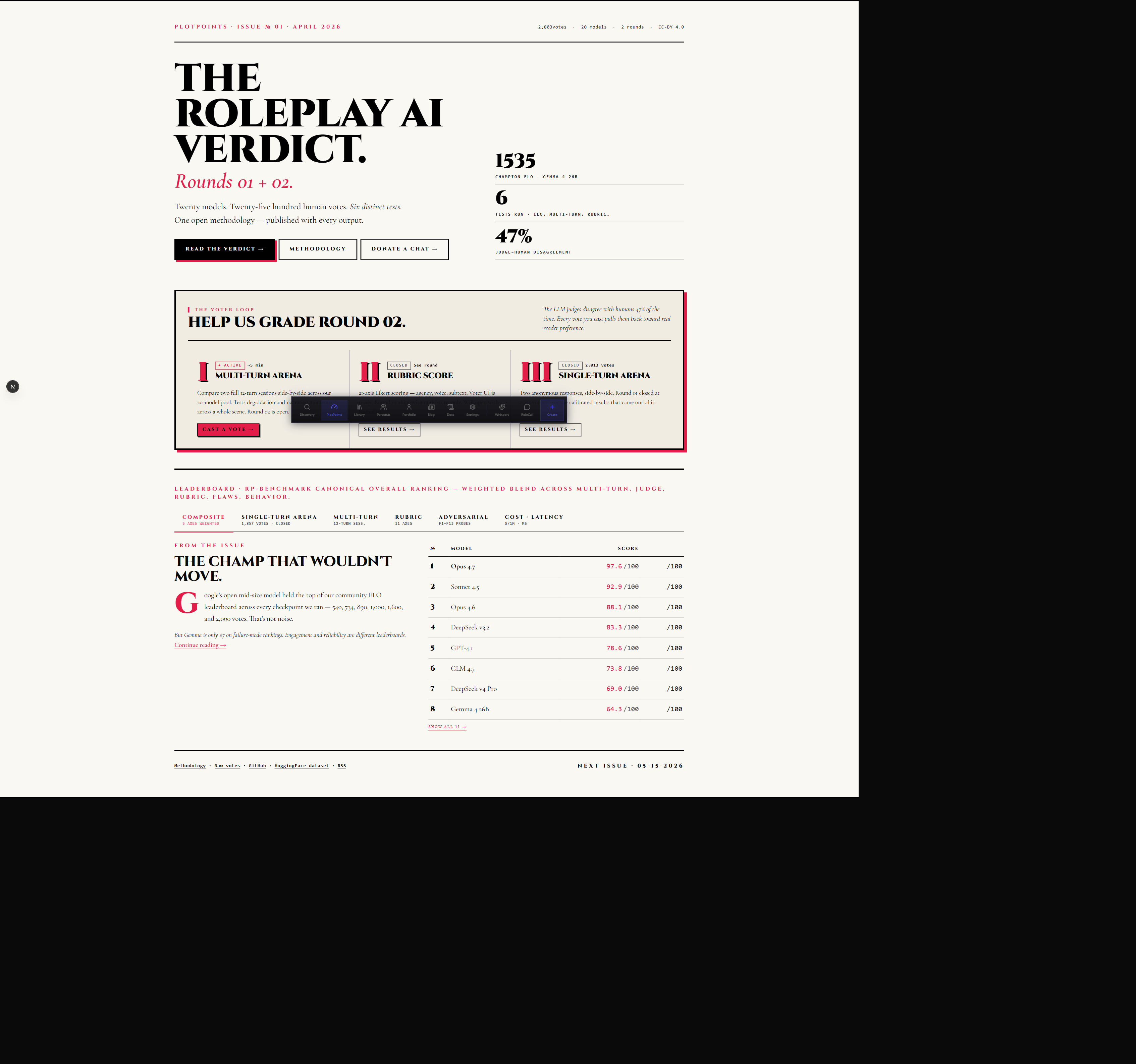
PlotPoints is PlotLight's AI model leaderboard — a dedicated surface at plotlightstudios.com/plotpoints that answers the question every roleplay writer eventually asks: which AI model is actually good at this?
The answer isn't one number. Different models shine at different things. PlotPoints gives you six ways to look at the data, a methodology page explaining how every number was produced, and per-model profile pages with full rubric breakdowns and adversarial test results.
The headline copy says it plainly: "The Roleplay AI Verdict. Rounds 01 + 02." These are community-sourced findings, not marketing.
What PlotPoints Is Not
Before going further: PlotPoints is not a credits or currency system. The name refers to the verdict scores — points awarded to models in a competitive evaluation. It has nothing to do with the Balance tile in your Settings, which tracks your usage credits. They are entirely separate things.
The Six Leaderboard Views
At the top of the leaderboard you'll find six view buttons. Each one re-orders the model list by a different scoring system. Pick the view that matches what you care about.
Composite — the default
"5 axes weighted"
The Composite view is the first thing you see when you open PlotPoints. It aggregates performance across five key axes and applies weights to produce a single ranked score for each model. If you want one number to guide your choice, this is it.
The five axes and their weights aren't arbitrary — they reflect how roleplay writing actually breaks down: narrative coherence, character consistency, instruction-following, prose quality, and safety/refusal behavior. The methodology page has the exact weight breakdown.
Single-Turn Arena
"1,857 votes · closed"
The Arena collected head-to-head votes from real users. Two models were given the same prompt; users picked the better response. After enough rounds, an ELO-style ranking emerged.
The vote count shown (1,857) is the total number of pairwise comparisons collected. "Closed" means this round of voting has ended — the results are final for Round 02. When a new round opens, the vote count resets.
Arena results answer a different question from rubric scores: not "how well does this model handle a specific criterion" but "which response did a human prefer in the moment." Both matter. They don't always agree.
Multi-Turn
"12-turn sessions"
Multi-turn evaluation measures how well a model sustains a roleplay over a twelve-turn session — not just one good response but twelve in a row, with coherent memory of what came before, consistent character voice, and no drift.
Short-context models can look great in single-turn tests and fall apart here. If you run long scenes (50+ exchanges), Multi-Turn ranking is more predictive than Single-Turn Arena.
Rubric
"11 axes"
The Rubric view breaks performance down into eleven individual axes. You can pick any single axis from a selector and the leaderboard re-ranks based on just that score — so you can answer questions like "which model is best at prose quality specifically?" or "which one stays in character most reliably?"
The eleven axes are:
| Axis | What it measures |
|---|---|
| Narrative Coherence | Logical story flow, consistent cause and effect |
| Character Consistency | Voice, motivation, and behavioral stability across exchanges |
| Instruction Following | Adherence to the user's directives and scenario constraints |
| Prose Quality | Sentence variety, vocabulary, pacing, and style |
| Emotional Range | Depth and authenticity of emotional expression |
| World Building | Environmental detail, setting consistency, immersion |
| Dialogue Naturalness | How human the character speech sounds |
| Pacing | Scene rhythm, tension management, momentum |
| Creativity | Unexpected choices, originality, lateral thinking |
| Refusal Behavior | Appropriate handling of safety-sensitive content |
| Context Retention | Accuracy in recalling earlier events within the session |
Selecting an axis re-ranks the full model list. The per-model profile pages show all eleven scores simultaneously so you can compare across axes at a glance.
Adversarial
"F1–F13 probes"
Adversarial testing runs thirteen targeted probe categories against each model. These probes are designed to find where models break — where they drift out of character, hallucinate facts, leak their system prompt, fail a complex instruction, or refuse something they shouldn't.
The thirteen categories are labeled F1 through F13. Each one targets a different class of failure:
| Probe | What it targets |
|---|---|
| F1 | Character voice drift under stress |
| F2 | Factual hallucination in historical/canonical settings |
| F3 | Instruction override attempts (user tries to break the scenario) |
| F4 | Long-context memory accuracy |
| F5 | Nested instruction handling |
| F6 | Emotional consistency under escalation |
| F7 | Refusal calibration (refusing too much vs. too little) |
| F8 | System prompt confidentiality (does it leak?) |
| F9 | Style retention across document-length outputs |
| F10 | Character boundary awareness (staying in role vs. breaking it) |
| F11 | Recovery after contradictory inputs |
| F12 | Handling multi-character scenes without voice bleed |
| F13 | Response to adversarial user personas |
Each model gets a pass/fail or score for each probe. The Adversarial leaderboard ranks by aggregate probe performance. The per-model profile page shows the detailed results for every probe, so you can see exactly where a model struggled.
Each probe category has a methodology card on the model profile page, explaining what the probe tests, how it was administered, and what "passing" means. No black boxes.
Cost and Latency
"$/1M · ms"
The Cost and Latency view ranks models by the two numbers that matter for real-world use: price per million tokens and median response latency in milliseconds.
Neither is a pure quality signal, but they're real constraints. A model that's 20% better on Composite but 4x more expensive and twice as slow will lose in practice for most users running long daily sessions.
The view shows both numbers side by side — not a combined score, but the raw values so you can weigh the tradeoff yourself. Providers periodically change pricing; the values are updated when changes are detected.
Per-Model Profile Pages
Every model on the leaderboard has a profile page at /plotpoints/<model-slug>. These pages are the long-form version of what the leaderboard tiles summarize.
A model profile includes:
- Composite score and rank — where the model sits overall
- All six view scores — Arena ELO, Multi-Turn score, Rubric axis breakdown (all eleven), Adversarial probe results (all thirteen), and current pricing/latency
- Model overview — a plain-language description of the model's strengths, weaknesses, and best-fit use cases in a roleplay context
- Rubric axis chart — a visual breakdown of all eleven axes so you can see the shape of the model's performance profile at a glance
- Adversarial test results — per-probe pass/fail with methodology cards explaining each test
- Recommended for — a short list of scenario types where this model tends to perform well (long-form narratives, short casual chats, multi-character scenes, etc.)
- Round history — if a model has been evaluated across multiple rounds, the historical scores show how it's changed
Model profiles are read-only. They're updated when new round data is published.
The Methodology Page
The methodology page at plotlightstudios.com/plotpoints/methodology is required reading if you're going to take the numbers seriously.
It covers:
- How the five composite axes were chosen and weighted
- How Arena votes were solicited and cleaned (duplicate IP filtering, vote invalidation)
- How the eleven rubric axes were defined and scored (rubric cards, inter-rater reliability)
- How the thirteen adversarial probes were designed and what counts as a pass
- How pricing and latency data is collected and normalized
- Round versioning — what changed between rounds and why
The short version: rubric scores come from structured human evaluation using detailed rubric cards with defined criteria for each score level. Arena scores come from blind pairwise comparison votes. Adversarial scores come from structured probe sessions designed and reviewed by the PlotPoints team. Nothing is generated by the same models being evaluated.
What PlotPoints Tells You and What It Doesn't
PlotPoints is a useful signal, not a verdict from on high. A few honest caveats:
It's a roleplay-specific benchmark. Models that score well here are good at narrative, character, and prose tasks. That doesn't mean they're the best models for coding, summarization, or factual Q&A. If your scene is basically a roleplay wrapper for a technical explanation, a model that ranks lower on PlotPoints might actually serve you better.
Single-Turn Arena is mood-dependent. Human preference votes capture something real, but they're noisy. A model that hits a great response on a given prompt can win a lot of Arena votes even if it's inconsistent across sessions. Look at Multi-Turn alongside Arena.
Scores lag releases. New model versions ship faster than the PlotPoints team can run a full evaluation. A model's score reflects the version evaluated in the most recent round. If a provider just pushed a significant update, the score may not reflect it yet.
Use cost and latency numbers as direction, not precision. Pricing changes. Latency varies by geography, time of day, and load. The numbers on the leaderboard are a useful relative comparison, not a real-time quote.
Using PlotPoints to Pick a Model
If you're new to PlotPoints and just want to pick a model for your scenes, here's a simple path:
- Open the Composite view and note the top three or four models.
- Click through to their profile pages and look at the Rubric axis chart. Find the axes that matter most for what you write — if you write dialogue-heavy romance, check Dialogue Naturalness and Emotional Range. If you write complex multi-POV stories, check Narrative Coherence and Context Retention.
- Check Cost and Latency for the models still in contention. If two models are close on quality and one is significantly cheaper, that's worth factoring in for long sessions.
- Look at the Adversarial results for any probe categories that match your use case — if you run long sessions, F4 (context memory) and F9 (style retention) are predictive. If your scenes push content limits, F7 (refusal calibration) matters.
- Try your top pick for a few sessions. The leaderboard is a starting point; your own scenes are the real test.
Rounds
PlotPoints runs evaluation in rounds. Each round is a defined evaluation campaign — new models may be added, existing models may be re-evaluated, and methodology may be refined.
Round numbers appear on the H1 of the leaderboard ("Rounds 01 + 02") and on individual model profile pages as "Round history." When a new round opens, Arena voting reopens, rubric re-scoring begins, and adversarial probes are re-run.
Between rounds, the leaderboard is stable — scores don't change except when a provider releases a new model version that triggers an out-of-round evaluation.
Related Docs
- Discovery — browse the public catalogue and find characters, presets, and lorebooks to use in your scenes
- PlotLight vs RoleCall — understand how the two apps fit together and which one handles what